Claude Multiagent Orchestration : Construire une Flotte d'Agents Spécialistes en 2026
Anthropic lance Multiagent Orchestration dans Claude Managed Agents : un lead agent qui orchestre des spécialistes en parallèle sur un filesystem partagé. Guide complet 2026.
Sommaire
---
Pourquoi Multiagent Orchestration arrive maintenant {#introduction}
Le 7 mai 2026, Anthropic a annoncé une mise à jour majeure de Claude Managed Agents avec trois nouveautés : Dreaming, Outcomes, et Multiagent Orchestration. Cette dernière est celle qui ouvre la voie à des charges agentiques que personne n'arrivait à automatiser de bout en bout jusqu'ici.
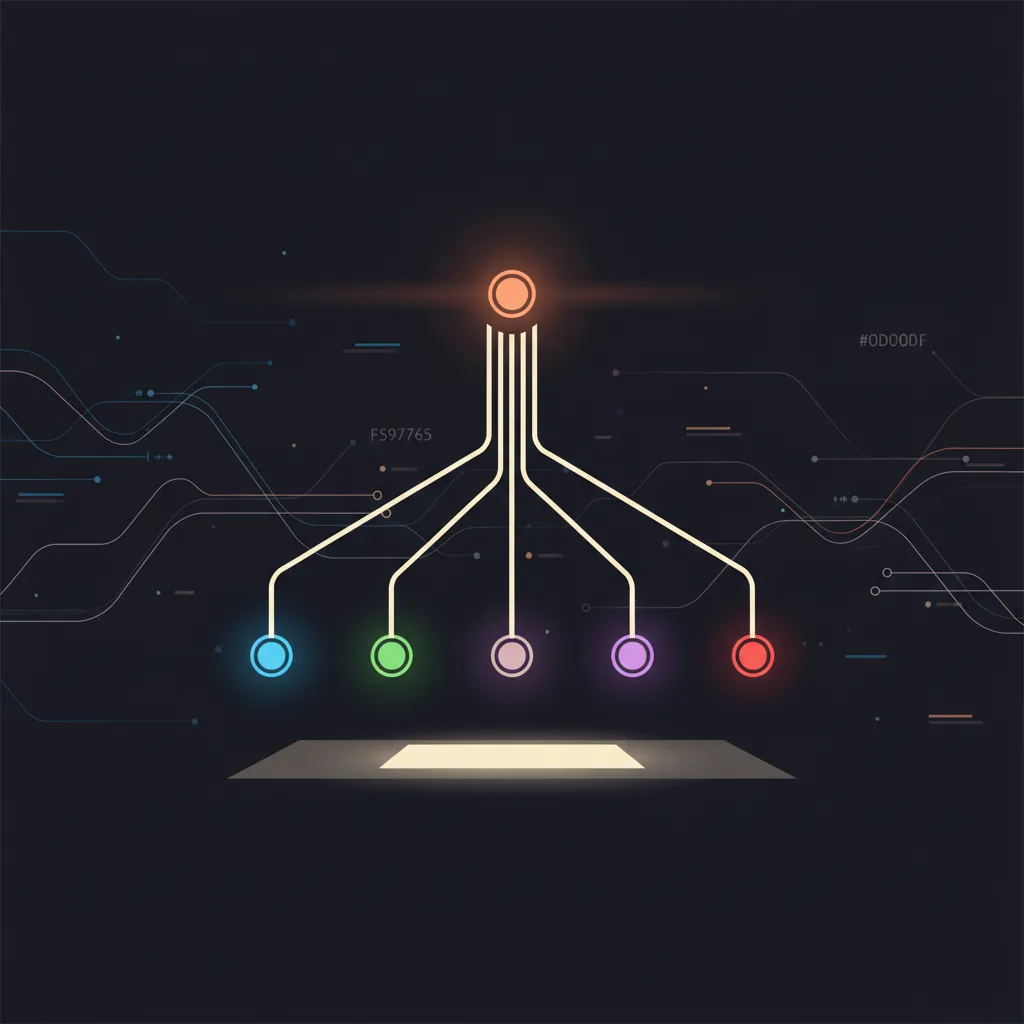
Le principe : pour les tâches qu'un seul agent ne peut pas faire correctement, on décompose. Un *lead agent* lit l'instruction, planifie, puis délègue chaque sous-tâche à un *spécialiste* — un agent dédié avec son propre modèle, son propre system prompt et ses propres tools. Les spécialistes tournent en parallèle, écrivent leurs résultats sur un filesystem partagé, et le lead agent agrège tout pour la réponse finale.
C'est l'extension naturelle des Agent Teams de Claude Code, mais cette fois packagée comme une feature de production cloud avec scaling, observabilité et facturation intégrés.
---
L'architecture lead + spécialistes expliquée {#architecture}
Le rôle du lead agent
Le lead agent est le chef d'orchestre. Il reçoit la requête utilisateur initiale et passe la majorité de son temps à :
Le lead n'exécute pas le travail de production. Il pilote.
Le rôle des spécialistes
Chaque spécialiste est un agent autonome avec :
Les spécialistes ne se parlent pas entre eux. Ils communiquent via les fichiers produits, lus par le lead.
Le schéma global
┌───────────────────┐
│ LEAD AGENT │
│ (Opus 4.7) │
│ Plan + dispatch │
└─────────┬─────────┘
│
┌─────────────────┼─────────────────┐
▼ ▼ ▼
┌──────────────┐ ┌──────────────┐ ┌──────────────┐
│ SPECIALIST A │ │ SPECIALIST B │ │ SPECIALIST C │
│ (Haiku 4.5) │ │ (Sonnet 4.6) │ │ (Opus 4.7) │
│ frontend │ │ backend │ │ tests │
└──────┬───────┘ └──────┬───────┘ └──────┬───────┘
│ │ │
└─────────────────┼─────────────────┘
▼
┌─────────────────────┐
│ SHARED FILESYSTEM │
│ /workspace/... │
└─────────────────────┘Chaque spécialiste écrit dans le workspace partagé. Le lead lit la production de chacun pour décider de la suite.
---
Comment déclarer une flotte d'agents {#declaration}
La config de l'agent managé
Côté Anthropic console (ou via SDK), vous déclarez l'orchestration comme suit :
{
"type": "multiagent",
"lead": {
"model": "claude-opus-4-7",
"system_prompt": "You are a lead engineer. Decompose the user request and delegate to specialists.",
"tools": ["filesystem", "specialist_dispatch"]
},
"specialists": [
{
"name": "frontend",
"model": "claude-sonnet-4-6",
"system_prompt": "You are a frontend engineer. You only edit files under src/components/ and src/pages/.",
"tools": ["filesystem", "code_execution", "playwright_mcp"]
},
{
"name": "backend",
"model": "claude-sonnet-4-6",
"system_prompt": "You are a backend engineer. You only edit files under src/api/ and src/services/.",
"tools": ["filesystem", "code_execution", "database_mcp"]
},
{
"name": "tester",
"model": "claude-opus-4-7",
"system_prompt": "You write unit and integration tests. Read what frontend and backend produced and add coverage.",
"tools": ["filesystem", "code_execution"]
}
],
"shared_workspace": "/workspace"
}Le tool `specialist_dispatch`
Le lead invoque les spécialistes via un tool natif :
{
"type": "tool_use",
"name": "specialist_dispatch",
"input": {
"specialist": "frontend",
"task": "Add a settings page at src/pages/Settings.tsx with form fields for theme and notification preferences. Persist via /api/user/settings.",
"expected_artifacts": ["src/pages/Settings.tsx", "src/components/SettingsForm.tsx"]
}
}Le parallélisme par défaut
Quand le lead dispatch plusieurs jobs dans la même réponse (plusieurs specialist_dispatch dans un seul turn), les spécialistes tournent en parallèle. C'est exactement le comportement attendu : le lead bat le rythme, les spécialistes travaillent simultanément.
Pour forcer le séquentiel, il suffit de dispatcher un seul job par turn et d'attendre l'artifact avant de dispatcher le suivant.
---
Le filesystem partagé : la clé du parallélisme {#filesystem}
Pourquoi un filesystem et pas du message-passing ?
Anthropic a fait un choix d'architecture explicite : les spécialistes communiquent par fichiers, pas par messages directs entre agents. Trois raisons :
Le workspace est une vraie sandbox
Le filesystem partagé est une sandbox Linux isolée par projet. Chaque spécialiste y a un accès complet en lecture/écriture, mais ne voit que le workspace de l'agent en cours. Les commandes bash, git, python tournent dedans.
C'est ce qui permet d'avoir un *vrai* workflow de dev : un spécialiste git checkout une branche, un autre git apply un patch, le tester pytest la suite, tout dans le même contexte filesystem.
La convention de répertoires
Anthropic suggère une structure type :
/workspace
├── repo/ # Code du projet
├── artifacts/ # Sorties produites par les spécialistes
│ ├── frontend/
│ ├── backend/
│ └── tester/
├── plan.md # Plan écrit par le lead
└── status.json # État courant de l'orchestrationLe lead écrit plan.md au démarrage, met à jour status.json à chaque dispatch, et lit les sous-répertoires pour synthétiser. Les spécialistes écrivent sous leur namespace propre.
Le concurrency model
Les spécialistes peuvent écrire en parallèle dans des fichiers différents. Si deux spécialistes tentent d'écrire le même fichier, le dernier écrivain gagne — sans erreur. C'est au lead de découper proprement les responsabilités pour éviter ce cas.
---
Cas d'usage où le pattern brille {#cas-usage}
Anthropic identifie quatre familles de cas où Multiagent surclasse un agent unique.
1. Recherche et review approfondie
Un projet de R&D où chaque spécialiste creuse un angle :
Bénéfice : chaque spécialiste tourne dans son contexte propre sans saturer la fenêtre du lead.
2. Nouvelles features ou modules
Construction d'une feature full-stack :
Le lead lit les artifacts de chaque, vérifie la cohérence (ex: la signature de l'endpoint dans le backend matche le contrat utilisé par le frontend), et boucle si nécessaire. C'est exactement le cas où le développement parallèle accélère drastiquement.
3. Debug avec hypothèses concurrentes
Quand un bug est mystérieux, plusieurs hypothèses sont testables en parallèle :
Chaque spécialiste écrit son rapport, le lead arbitre. Sans multiagent, l'agent unique perd un temps fou à tester séquentiellement.
4. Cross-layer coordination
Refactoring qui traverse frontend, backend et tests. Le lead découpe par couche, dispatch en parallèle, puis recompose. Les conflits de signature sont arbitrés au moment de la synthèse.
---
Multiagent vs Agent Teams vs Sub-agents {#comparaison}
Trois patterns existent dans l'écosystème Claude. Voici comment ne pas les confondre.
| Aspect | Sub-agents | Agent Teams (Claude Code) | Multiagent (Managed) |
|---|---|---|---|
| Plateforme | Claude Code CLI | Claude Code CLI | Claude Managed Agents (cloud) |
| Hiérarchie | 1 main + N sub | 1 lead + N teammates | 1 lead + N specialists |
| Communication | Sub renvoie au main | Teammates entre eux | Via filesystem partagé |
| Contexte | Sub a contexte isolé | Teammate a contexte isolé | Specialist a contexte isolé |
| Tools | Hérités du main | Spécifiques par teammate | Spécifiques par specialist |
| Parallélisme | Limité | Oui mais experimental | Oui, natif |
| Filesystem | Local dev | Local dev | Sandbox cloud isolée |
| Observabilité | Logs CLI | Logs CLI | Dashboards intégrés |
| Production-ready | Pour scripts CLI | En preview | Oui, en bêta publique |
Pour aller plus loin sur les sub-agents, voir notre guide pratique des sub-agents. Pour Agent Teams, consultez l'article Agent Teams pour le travail parallèle.
---
Limites, coûts et observabilité {#limites}
Le coût composé
Multiagent ne réduit pas mécaniquement le coût. Chaque spécialiste ajoute son propre coût d'inférence, plus celui du lead.
Pour une tâche moyenne :
Comparé à un seul Opus qui aurait fait toute la tâche en 50K tokens, vous payez plus. Mais vous gagnez :
L'arbitrage vaut le coup pour les tâches longues ou critiques. Pour les requêtes simples, un agent unique reste plus économique.
La latence cumulée
Le lead doit attendre le plus lent des spécialistes dispatchés en parallèle avant de pouvoir synthétiser. Si vous mettez 1 spécialiste rapide + 1 spécialiste long, la latence finale = celle du long. Calibrez la décomposition pour éviter les goulots.
Observabilité intégrée
Anthropic fournit dans le dashboard Managed Agents :
Pour comparer aux métriques Claude Code, voir notre article API Analytics et métriques d'équipe.
Les limites de bêta
Au 14 mai 2026, Multiagent Orchestration est en bêta publique. Quelques limites connues :
---
Bonnes pratiques de mise en production {#bonnes-pratiques}
1. Découper par responsabilités, pas par fichiers
Un spécialiste frontend doit avoir une mission claire : "tout ce qui touche à l'UI". Pas "les fichiers X, Y, Z". Le découpage par responsabilités survit au refactoring, le découpage par fichiers casse à la première restructuration.
2. Donner un workspace propre à chaque dispatch
Avant chaque dispatch, le lead écrit un task.md dans le sous-répertoire du spécialiste. Ce fichier contient :
C'est l'équivalent d'un ticket Jira par spécialiste, et c'est ce qui rend l'orchestration auditable.
3. Vérifier les artifacts au lieu de croire le rapport
Le lead doit lire le fichier produit par le spécialiste, pas se fier au résumé textuel renvoyé. Les spécialistes peuvent dire "j'ai fait X" sans avoir réellement écrit. Vérifiez le filesystem.
4. Combiner avec Outcomes
Pour les agents en production avec un SLA de qualité, combinez Multiagent avec Outcomes : la flotte produit l'artifact, le grader le vérifie, le lead ré-itère si la rubrique fail. Patron de production très robuste.
5. Limitez la profondeur de la hiérarchie
Lead → spécialistes = 2 niveaux. Au-delà (spécialiste qui re-dispatch à des sub-spécialistes), l'orchestration devient incompréhensible et le coût explose. Si vous ressentez le besoin, c'est un signe qu'il faut redécouper.
6. Versionnez la config de la flotte
Comme un fichier Terraform, la config multiagent est code. Versionnez-la en Git, faites du PR review dessus, déployez en blue-green pour comparer deux configurations sur des tâches identiques.
7. Investissez dans le system prompt du lead
Le lead est le SPOF qualité de l'orchestration. Un mauvais découpage, un mauvais dispatch, et la flotte produit n'importe quoi. Investissez 70% de votre prompt engineering sur le lead, 30% sur les spécialistes.
---
Anti-patterns à éviter {#anti-patterns}
Anti-pattern 1 : trop de spécialistes pour la même tâche
Avoir 8 spécialistes pour une tâche qui en demande 2 ralentit (lead doit lire 8 artifacts) et coûte cher. Commencez petit : 2-3 spécialistes max, ajoutez au fur et à mesure des besoins observés.
Anti-pattern 2 : spécialistes qui se chevauchent
Si frontend_agent et ui_agent ont des missions qui se recouvrent, ils vont écrire dans les mêmes fichiers et se piétiner. Le découpage doit être strict et orthogonal.
Anti-pattern 3 : lead qui fait le travail
Un lead qui finit par éditer lui-même du code "parce que c'est plus rapide" est le symptôme d'une mauvaise délégation. Le lead doit rester abstrait — sinon réutilisez un agent simple, c'est moins cher.
Anti-pattern 4 : pas de plan écrit
Si le lead dispatche sans avoir écrit plan.md au préalable, vous perdez la trace de la stratégie. Toujours forcer le lead à écrire son plan avant le premier dispatch.
Anti-pattern 5 : ignorer les conflits filesystem
Deux spécialistes qui éditent le même fichier en parallèle, sans coordination via le lead, c'est garanti que l'un écrase l'autre. Détectez ces patterns dans vos logs et redécoupez.
Anti-pattern 6 : utiliser Multiagent pour tout
Pour un script simple, une API call directe à Claude suffit. Multiagent prend tout son sens à partir de tâches > 30 minutes ou > 5 fichiers à toucher. En-deçà, c'est de la sur-ingénierie.
---
FAQ {#faq}
Multiagent Orchestration est-il dispo dans Claude Code CLI ?
Non, c'est une feature des Managed Agents (cloud). L'équivalent CLI est Agent Teams, qui partage la même philosophie mais tourne en local.
Peut-on mélanger des modèles Anthropic et d'autres providers ?
Non, tous les agents de la flotte sont des modèles Claude (Haiku, Sonnet, Opus, dans leurs versions disponibles). C'est une feature native Anthropic.
Combien coûte une orchestration moyenne ?
Très variable selon la complexité. Pour une feature full-stack de taille moyenne (1 lead Opus + 3 spécialistes Sonnet), comptez 0,50-2 USD par run. Pour de la recherche profonde avec Opus partout, jusqu'à 5-10 USD.
Les spécialistes peuvent-ils invoquer le Advisor Tool ?
Oui. Chaque spécialiste est un agent complet, donc peut activer le Advisor Tool pour consulter un Opus advisor sur ses décisions. Pattern puissant : flotte de Sonnet + advisor Opus = qualité Opus, prix Sonnet.
Peut-on lancer une flotte en mode interactif ou seulement programmatique ?
Les deux. Vous pouvez attaquer via API/SDK pour de l'automation (cron, webhooks), ou depuis la console Anthropic pour des runs ad-hoc avec UI de monitoring.
Le filesystem partagé est-il persistant entre runs ?
Non, par défaut chaque run a un workspace neuf. Vous pouvez configurer un workspace persistant pour les agents long-running (ex: un agent qui maintient un repo et reprend là où il s'était arrêté).
Comment debugger une flotte qui produit n'importe quoi ?
Trois étapes : (1) lire le plan.md du lead pour vérifier le découpage, (2) inspecter les tasks dispatchées dans la timeline du dashboard, (3) lire les artifacts produits par chaque spécialiste. 80% des bugs viennent d'un mauvais découpage du lead.
Peut-on intégrer des outils MCP ?
Oui, chaque spécialiste peut être configuré avec des serveurs MCP propres. Très utile pour donner accès au database, à GitHub, à Slack, etc. selon le rôle.
La flotte est-elle déterministe ?
Non, à cause de la nature des LLMs. Deux runs sur la même tâche peuvent donner des plans différents. Pour la reproductibilité, utilisez temperature=0 et seedez si supporté, mais la variation reste possible.
Y a-t-il un équivalent open-source ?
Plusieurs frameworks tentent de reproduire le pattern (Crew AI, AutoGen, LangGraph). Aucun n'égale aujourd'hui l'intégration native avec Claude (filesystem partagé, observabilité, scaling auto). Pour un POC local, regardez plutôt Agent Teams intégré à Claude Code.
Quand Multiagent quittera-t-il la bêta ?
Anthropic n'a pas communiqué de date. Historiquement les features Managed Agents passent en GA 3-6 mois après l'ouverture bêta publique. Attente raisonnable : Q3/Q4 2026.
---
*Sources : Claude Blog "New in Claude Managed Agents : dreaming, outcomes, and multiagent orchestration" (7 mai 2026), Anthropic Managed Agents docs (platform.claude.com/docs/en/managed-agents/multi-agent), Code with Claude 2026 keynote, MindStudio "5 New Agent Features", AddyOsmani "The Code Agent Orchestra", RejoiceHub analysis.*
Reçois la cheatsheet Claude Code (gratuite)
Les 30 commandes, raccourcis et prompts que j'utilise tous les jours. Directement dans ta boîte mail.
Zéro spam. Désinscription en un clic.
Envie de maîtriser Claude Code ?
Rejoignez notre formation complète et apprenez à utiliser Claude Code comme un pro.
M'inscrire à la formation